-

背景
随着企业信息化的长期发展和建设,在每个成熟领域均出现了大量的应用系统,信息化系统已经成为企业的命脉,是企业生成和发展密不可分的一部分。其要求的业务联系性等级越来越高、故障回复时间越来越短,尤其伴随互联网业务的发展,对系统异常的容忍度也越来越低,这就要求IT部门从上层的业务应用到底层的基础设施都要做到全面的掌控,并能够及时的发现和解决问题。
系统运行状态和告警信息都是通过系统的运行日志承载的,众多系统每天会生成海量的日志数据,各企业将大量的日志信息遗弃或进行回档入库,并不能在实际的应用系统管理过程中充分发挥其价值,反而成为了一种负担。 -

解决方案
基于大数据平台技术构建统一的应用系统日志数据集市,充分利用大数据平台特性将企业内众多格式多样和不统一的日志数据源全部进行采集,并集中存储于大数据平台,包括:系统日志、网络日志、安全日志、应用系统运行日志、操作行为日志等等。
数据处理按照日志数据本身的特性和管理需要进行实时和非实时的数据处理方式,实现对海量历史数据的和实时数据的分析,协助系统管理人员实现对应用系统运行过程中出现的各种问题的敏捷洞察,快速定位及排障,并能够通过对历史数据的演变过程及时发现未来可能出现的异常状况。
通过聚类、回归分析、关联规则、神经网络等算法实现对海量日志数据的分析可视化和深度挖掘,、完成对应用系统全面监控、预警、故障溯源、统计分析等功能。充分利用机器学习和人工智能分析方法,实现对应用系统运行的趋势分析,在容量规划、性能优化、客户满意度等方面全面发力,提升IT部门的运维管理能力,提升企业信息化管理水平。 -
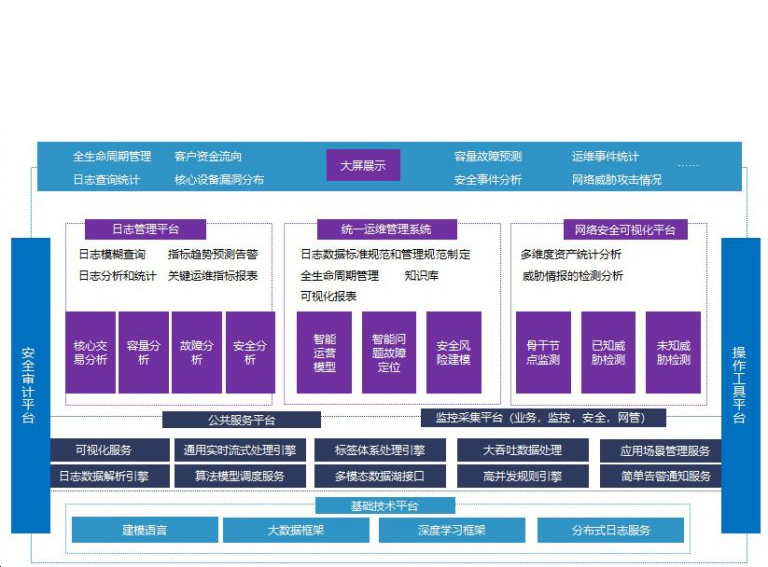
系统架构
基础数据平台基于大数据平台框架,在深度学习、人工智能算法、分布式日子服务等方面提供基础功能模块支撑。
在日志采集模块针对各类应用系统通过可延展的日志采集服务、从日志源采集日志。用户只需配置源地址、目的地址、收集规则等简单配置即可实现日志的高可靠、高可用采集。
采集到的日志通过日志处理模块,通过日志接入消息服务Kafka作为消息队列传递给Spark Cluster对日志数据进行计算处理,按照日志数据的采集时间分为热数据(7~30天)、温数据(30~90天)和冷数据(90天以上),分别、将处理后的数据写入到ElasticSearch Cluster、Hive、HDFS中进行保存。
日志分析模块首先通过日志数据治理模块对数据进行清洗、规则校验在通过高速分析引擎对日志数据进行各类分析模型进行关联分析、故障分析、容量分析、业务支撑分析等。
在应用与展示模块,通过数据可视化展示模块将告警信息、趋势信息等各种KPI指标进行集中呈现。 -

方案价值
1. 充分发掘数据价值
全面收集企业日志数据,通过关联、聚类等算法对海量日志数据进行分析挖掘,全面提升数据的可用性、易用性。
2. 提高工作效率
对系统层、网络层、应用层等各层级的日志数据进行采集,实现了全方位日志统一管理,支持对各种精确和模糊查询;根据运维规范和业务管理规范形成了多维度的数据分析,对已知关注的KPI指标进行直接的呈现。
3. 全面的数据可视化
提供故障分析、业务链路分析、安全评估分析、容量规划分析、趋势预警分析等各类直观的可视化图表,各种情况直观呈现,极大提升管理效率。
4. 提升运营管理能力
通过对日志数据的管理和挖掘,发挥其最大价值,并可以根据实际使用情况不断演进,合理制定企业IT发展战略。
